What Is a Kubernetes Operator?
Kubernetes Operators are a way to package, deploy, and manage Kubernetes applications. This includes Kubernetes applications deployed on Kubernetes and those that are managed using the Kubernetes API or kubectl.
A Kubernetes Operator is a controller specific to an application, which extends the Kubernetes API, letting you generate and manage instances of a complex application. It builds on the concept of a resource and controller in Kubernetes, but adds domain-specific information that can help you fully automate the lifecycle of the application.
Why are Kubernetes Operators Important?
In a typical use case, Kubernetes manages stateless applications, such as web servers, without requiring in-depth knowledge of their workings. Here, operators are not needed.
However, stateful applications such as databases and monitoring systems require domain-specific knowledge that the standard Kubernetes tooling does not possess. You need to add this information to scale, update and dynamically reconfigure these applications, including compute, storage, and networking resources.
Kubernetes operators can manage and automate the lifecycle of a stateful application by adding this domain specific knowledge into Kubernetes extensions.
Kubernetes operators can standardize complex processes, making them scalable and repeatable, and eliminating tedious manual management tasks.
How Does a Kubernetes Operator Work?
Operators are application-specific controls. They represent an extension of the Kubernetes API that lets you build, configure and manage complex application lifecycles, typically for operations or site reliability teams.
Operators use controllers to see the behavior of objects in the Kubernetes environment. These are a bit different from regular controllers, because they track custom objects, also known as custom resources (CRs). A CR is another extension of the Kubernetes API, which lets you store structured data that represents a desired application state.
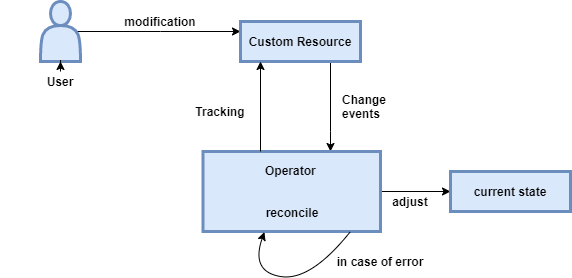
Operators continuously track cluster events related to certain types of custom resources. An operator can track add, update, or delete events. When the operator sees changes in the environment, actions are taken in the custom controller to bring the Kubernetes cluster or external system to the desired state (this is known as the “reconciliation loop”).
Kubernetes Operator Example
etcd is a core Kubernetes component that stores cluster configuration. It is managed by the Etcd Cluster Operator (see source code on Github), an Operator used to automatically create and manage etcd instances in Kubernetes.
The Etcd Cluster Operator provides an API based on custom resource definitions (CRDs), letting you use Kubernetes resources to define etcd clusters and manage them using Kubernetes native tools.
etcd is a distributed key-value data store, which achieves high availability using the following rules:
- Each etcd instance has a separate failure domain for computing, storage, and networking
- Each instance of etcd has a unique name on the network
- Any instance of etcd can access any other instance on the network
- Each instance of etcd is able to discover all other instances
In addition to these rules, scaling up or down in an etcd cluster requires certain actions, and before adding/removing instances, it needs to post changes to the cluster using the etcd management API.
Data backups are done using the “snapshot” endpoint, provided by the etcd management API, which streams a backup file when it is accessed. To restore from backup, a tool called etcdctl is provided as part of the backup file, and in the data directory of each etcd host.
As you can see, this management is outside the scope of a regular StatefulSet. This is the type of complex, automated functionality that an Operator can provide.
Best Practices for Writing Kubernetes Operators
Use the Operator SDK
While you can code Operators by hand, Kubernetes provides an Operator SDK that can be used to quickly create a new operator, with boilerplate code and YAML configuration. It also provides a useful Reconcile function for custom resources the Operator needs to manage. This function is similar to a main function on a regular software component.
It is a good idea to consistently use the Operator SDK, so you can more easily collaborate when committing code to several Operators, and to create a smooth learning curve for developers working on Operators. Once a developer has used the Operator SDK, it will be easier to work with any Operator created using the SDK.
Keep Reconcile Functions Clean
When using the Reconcile function, there are several possible return codes, each resulting in specific Operator behavior. The Operator watches the return values of the Reconcile function and may either continue the reconcile loop, delay it, or end the loop.
It may seem convenient to add business logic to the Reconcile function, but this can interfere with the core functioning of the Operator. Keep Reconcile functions clean to make it easy to determine what will be the output of the function. Or if you do add business logic, make sure you consistently return the same output values, allowing the operator to correctly maintain the reconcile loop.
Modify One Custom Resource at a Time
Whenever a custom resource changes, whether because of a user action or because of something you did in the Reconcile function or a subroutine, the reconcile loop runs again. For example, if you need to update the ID of a resource, the reconcile loop will run again with the updated version of the resource.
This means that changing multiple custom resources can cause race conditions—if there is parallel processing, there could be multiple simultaneous requests to the same resource in a single line of your code. Or even if requests are not parallel, numerous successive changes to the same operator can make the Operator extremely busy. To prevent this, modify resources with care.
Kubernetes Operators with Kubermatic
At Kubermatic, we extend the Operators paradigm beyond applications to manage the clusters themselves. With our open source Kubermatic Kubernetes Platform, we are using Kubernetes to manage Kubernetes.
On a technical level, the cluster state is defined in Custom Resource Definitions then stored within etcd. A set of controllers and their associated reconciliation loops watch for changes or additions to the cluster state and update each as required. All state is stored in a “Master Cluster”. When a new user cluster is defined, the control plane components (API server, etcd, Scheduler, and Controller-Manager) are created as a deployment of containers within a namespace of the master cluster. The worker nodes of the user cluster are deployed by machine-controller which implements Cluster API to bring declarative creation, configuration, and management to worker nodes.
Operators allow Kubermatic Kubernetes Platform to automate not only the creation of clusters, but also their full life cycle management. Thanks to its specific architecture, KKP can be used to manage tens of thousands of clusters with minimal operational effort.